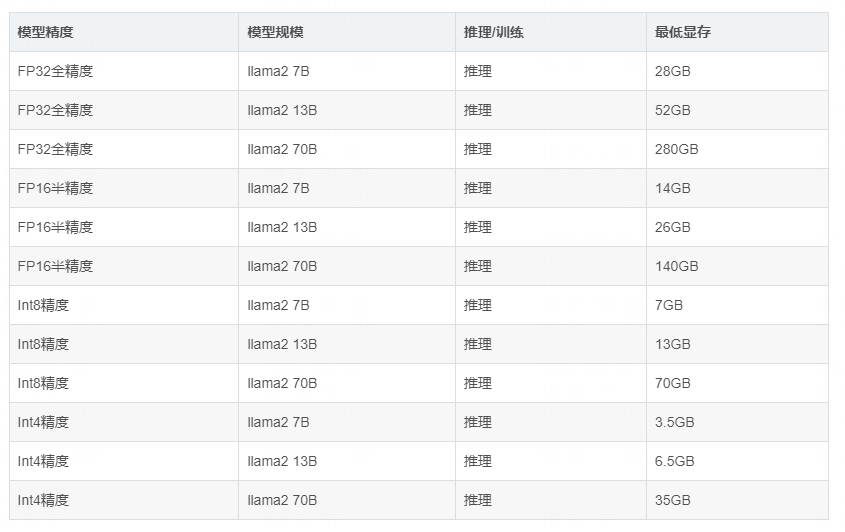
全精度(float32):每个参数需要32位(4字节)的存储空间。因此,对于7B参数的模型,理论上需要 7B * 4字节 = 28GB 的显存。这仅考虑了模型参数本身,并未包括其他运行时所需的额外空间,如优化器状态、激活等。
半精度(float16):在半精度下,每个参数占用16位(2字节)。这样,7B模型的显存需求降低到 7B * 2字节 = 14GB。
更低精度:随着精度的降低,显存需求进一步减少。例如,8位精度(int8)和4位精度(int4)的模型分别需要 7B * 1字节 = 7GB 和 7B * 0.5字节 = 3.5GB 的显存。
NVIDIA A100:拥有80GB的显存,适合运行大规模的LLMs,如Llama 2 7B模型。A100的高内存带宽和强大的计算能力使其成为大型模型训练的理想选择。
RTX 4090:作为消费级市场的顶级显卡,RTX 4090提供了24GB的显存,对于7B规模的模型来说,可能需要在精度上做出妥协,或者利用模型并行技术来分散显存需求。
RTX 3090:拥有24GB显存的RTX 3090也是一个不错的选择,尤其是在半精度或更低精度下运行模型时。
相关标签:
相关推荐

中国面临人工智能技术带来的潜在就业问题时,可以考虑以下几种策略来保护和转型现有劳动力市场:教育和培训:更新教育体系,让未来的工作力准备好应对AI时代。提供继续教育和职业培训,尤其是在高科技、AI和数据分析领域,来帮助现有员工提高技能和适应性。职业重塑和转型:为那些最有可能被AI技术取代的行业和职业提供转型...
最近的一份来自英国公共政策研究所(IPPR)的研究警告称,如果政府政策保持当前状态,英国可能会因为人工智能的发展而失去多达800万个工作岗位。这一数据表明了人工智能技术变革的巨大冲击,不仅改变了工作领域的结构,而且对劳动力市场造成深远的影响。对中国来说,英国的这一变化既是一个警示也是一个机遇。首先,英国将因...
蔡崇信在讨论中国人工智能(AI)的发展时强调,英伟达(NVIDIA)芯片对于中国AI行业的发展至关重要,特别是对于云计算业务的重要性。以下是为中国AI发展至关重要的芯片技术:高端GPU(图形处理单元):英伟达等公司生产的GPU在AI领域尤其受到青睐,因为它们能够提供大量并行处理能力,这对于训练机器学习模型来说非常关键。...
蔡崇信提到高端芯片出口限制对中国AI发展的影响是显著的,尤其是在以下几个方面:技术创新和研发受阻:AI的发展极大依赖于强大的计算能力,而高端芯片是提供这种计算能力的关键。出口限制意味着中国AI公司可能无法获得最先进的芯片技术,这直接影响了这些公司在深度学习、机器学习及其他AI相关技术领域的研究和开发能力。成...

